 Back
Back
Introduction
Big data is a term used for Datasets that are very large or complex that customary data processing techniques are insufficient to deal with them. Big Data are data sets which are beyond the power of storage and processing capacity. The challenges of big data are analyzed, storing, visualization etc... The important aspect is gathering of useful information from the generated huge data. Collecting and analyzing
Big Data helps organizations for enhanced insight, decision-making, and better process automation. Storing and analyzing big data is not possible using the traditional databases and programming languages. However, storing and analyzing big data effectively is possible using Hadoop.
Emergence and Growth of Big Data Analytics

BIG DATA is a collection of huge amount of data which is identified mainly by 3 characteristics - Volume, Velocity, and Variety. Volume is referred as a quantity of data generated by social websites, government organizations, industries. Velocity is the speed at which the data is generated. Variety is the format of the data where the data formats of big data may be structured, semi-structured or unstructured.
Initially, as the Hadoop ecosystem took shape and started to mature, big data applications were primarily the province of large internet and e-commerce companies, such as Yahoo, Google, and Facebook, as well as analytics and marketing services providers. In ensuing years, though, big data analytics has increasingly been embraced by retailers, financial services firms, insurers, healthcare organizations, manufacturers, energy companies and other mainstream enterprises.

Big Data Analytics Benefits
Driven by specialized analytics systems and software, big data analytics can point the way to various business benefits, including new revenue opportunities, more effective marketing, better customer service, improved operational efficiency and competitive advantages over rivals. On a broad scale, data analytics technologies and techniques provide a means of analyzing data sets and drawing conclusions about them to help organizations make informed business decisions.
Big data analytics uses and challenges
Big data analytics applications often include data from both internal systems and external sources, such as weather data or demographic data on consumers compiled by third-party information services providers. In addition, streaming analytics applications are becoming common in big data environments, as users look to do real-time analytics on data fed into Hadoop systems through Spark's Spark Streaming module or other open source stream processing engines, such as Flink and Storm. It is used in many sectors such as Pricing, Retail habits, Out of Home Advertising, Politics, Weather, Infectious diseases, Internet of things, Social Media Analysis and Response, Security Intelligence and Fraud Prevention and in many other.
Big Data Veracity refers to the biases, noise, and abnormality in data Is the data that is being stored, and mined meaningful to the problem being analyzed. Inderpal feel veracity in data analysis is the biggest challenge when compares to things like volume and velocity.
Big data analytics technologies and tools
Hadoop:

Hadoop is a popular tool for analyzing big data. Hadoop is an open source framework which handles the big data in distributed storage and distributed processing environments. Storing of big data is done using Hadoop Distributed File System (HDFS). Handling of big data can be done using Hadoop’s MapReduce programming approach. However, writing and understanding java map-reduce application is difficult and hard to maintain. Hive is a relatively simple tool for analyzing big data.
Hadoop basically contains two parts: Map Reduce and HDFS (Hadoop Distributed File System)
Map Reduce:
MapReduce framework suitable for parallel Data processing in a distributed computing environment. MapReduce is a process of executing data with partitioning and aggregation of intermediate results. It works to process data in parallel in which splitting of data, distribution, synchronization and fault tolerance are handled automatically by the framework
A MapReduce framework can be categorized into mainly two steps such as:
Map Phase: Initially split the data into key-value pairs and fed into mapper which in turn process each key-value pair and generate intermediate output.
Reduce Phase: The Intermediate key-value pair first collected, sorted and grouped by key and generate values associated with each key.
HDFS(Hadoop Distributed File System)
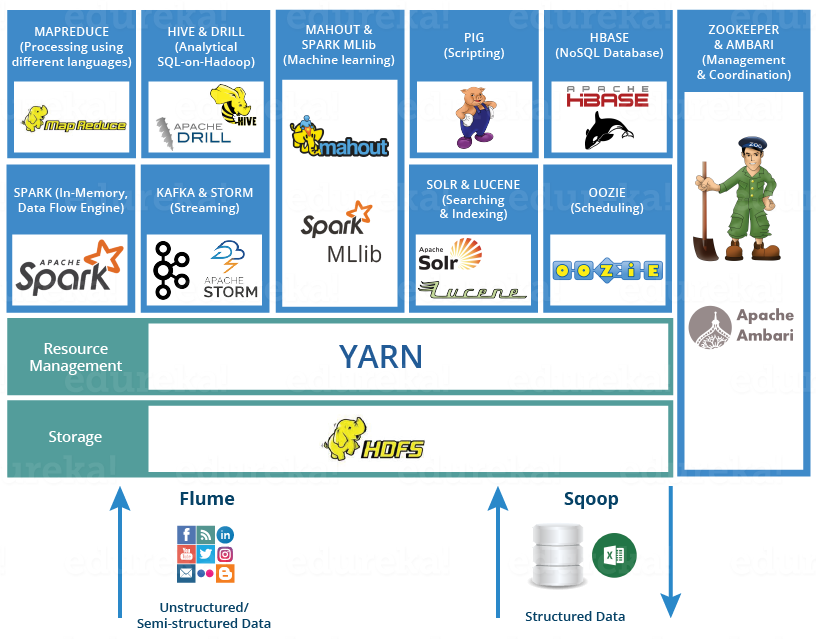
HDFS is an Apache Software Foundation project and a subproject of the Apache Hadoop project. HDFS lets you connect nodes (commodity personal computers) contained within clusters over which data files are distributed. You can then access and store the data files as one seamless file system. HDFS has many similarities with other distributed file systems but is different in several aspects. One noticeable difference is HDFS's write-once-read-many model that relaxes concurrency control requirements, simplifies data coherency, and enables high-throughput access.
It is suitable for distributed storage and processing, and also provides a command interface to interact with HDFS. The built-in servers of name node and data node help users to easily check the status of a cluster and the streaming access to file system data is provided and it also provides file permission and authentication. Data is stored in the Hadoop Distributed File System must be organized, configured and partitioned properly to get good performance on both extracts, transform and load (ETL) integration jobs and analytical queries. Bigdata using Hadoop concentrates on the use of MapReduce and Hive tools for analyzing it.
Big Data Analytics and the Future of Marketing and Sales:
Big data is known to be the largest game-changing opportunity in the global market today since the Internet went mainstream about two decades ago. There are a couple of companies that are using Big Data to create opportunities and its use along with analytics show rates of productivity and profitability of 5-6% higher than their competitors. The extraction of data set from both within and outside a company gives it an advantage and would aid in successful discovery. India’s big data analytics sector is expected to grow in multiples by 2025 and should reach as high as $16 billion from the present $2 billion according to the National Association of Software and Services.
Conclusion
By 2020, global big data market is expected to grow about 37 percent and this will be as a result of the increase in penetration of big data in diverse sectors, analytics services increase and the availability of big data services and solutions which are affordable to end users.
